Reasoning LLMs
Up until the end of 2024, if you wanted to have your LLM reason on a subject, you used "chain of thought" prompting, where you instructed it to analyze an issue by steps. This tended to produce more comprehensive answers or output. Enter DeepSeek R1 from China that was released on Jan 20, 2025. Not only was it less expensive to train, but it was also released as open-source. It leveraged reinforcement learning and "mixture of experts." This later term means it is able to parse out work to specialty sections of the LLM that improve efficiency. In general, reasoning LLMs are slower, particularly DeepSeek, because it iterates through multiple logic steps.
The emergence of specialized reasoning LLMs like DeepSeek R1, o3 mini, Claude 3.7 Sonnet Reasoning, QwQ 32B, and Gemini 2.0 thinking represents a significant shift in AI development, focusing on enhanced reasoning capabilities and efficiency. Unlike more generalized models like GPT-4o, these new LLMs are specifically designed to excel in complex problem-solving, mathematical calculations, and technical tasks. They often incorporate advanced training techniques, such as large-scale reinforcement learning and multi-stage training pipelines, to improve their reasoning abilities. This specialization allows them to achieve comparable or even superior performance to larger models in specific domains, while often being more cost-effective and faster. For instance, QwQ 32B reportedly matches the performance of much larger models at a fraction of the cost. Additionally, some of these models, like Claude 3.7 Sonnet, offer visible step-by-step reasoning, enhancing transparency and interpretability. This trend towards specialized reasoning models suggests a future where AI systems can be more tailored to specific tasks, potentially revolutionizing fields that require advanced analytical and problem-solving skills.
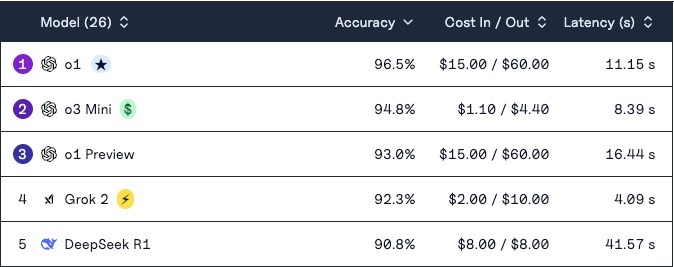
DeepSeek had done well in a variety of competitions. I came in fifth on the MEDQA Leaderboard as of 3/13/25 (shown below) and 84% for the MMLU-Pro leaderboard.
We are in the process of analyzing the use of DeepSeek on 162 complex medical scenarios found in the MMLU-Pro benchmark. DeepSeek and o3 mini are both available on Perplexity AI, so that is how we carried out our research. Preliminary results suggest an accuracy of greater than 90%. It leveraged an average of 16 references and 12 reasoning steps per query. There were no hallucinated references, but unrelated references were common. It appears that other reasoning LLMs do as well but are less transparent compared to DeepSeek. These scenarios are associated with 4-10 potential answers. We plan to also test DeepSeek on the same medical scenarios but without the answer supplied, which we believe is a better way to evaluate LLMs.The answers by DeepSeek could be considered "verbose" due to its multiple iterative steps. There is a new method called "chain of draft" that instructs the model to limit the wording of each step to only 5 words. It results in a faster answer but, in our experience, a less comprehensive result.
Below you can see the steps taken by DeepSeek to analyze a medical scenario. You begin with a prompt, and in this case, a medical scenario is pasted in for analysis. You then see a literature search, reasoning steps, and finally the answer with key analysis and conclusion.


Peng, Yifan, et al. “From GPT to DeepSeek: Significant Gaps Remain in Realizing AI in Healthcare.” Journal of Biomedical Informatics, no. 104791, Elsevier BV, Feb. 2025, p. 104791